Moderation API changelog
May updates: Rules, URL risk, & Wellness

This month: more control over moderation logic, real-time link safety, audio support, and a friendlier review queue.
Rules
Decide what happens to content based on any signal in the moderation response — policy flags, severity, author trust, language, URL risk. A few examples:
If user is trusted → Allow
If user is new and URL Risk is Flagged → Review
If Language is not English → Review
Hit Simulate to see how draft rules would have shifted recent decisions before saving.
Available on all plans. Read about the rules engine here.
URL Risk
A new policy that scores links in real time for phishing, malware, brand impersonation, and credential harvesting. URLs are pulled from text automatically — no separate field. Pairs naturally with Rules.
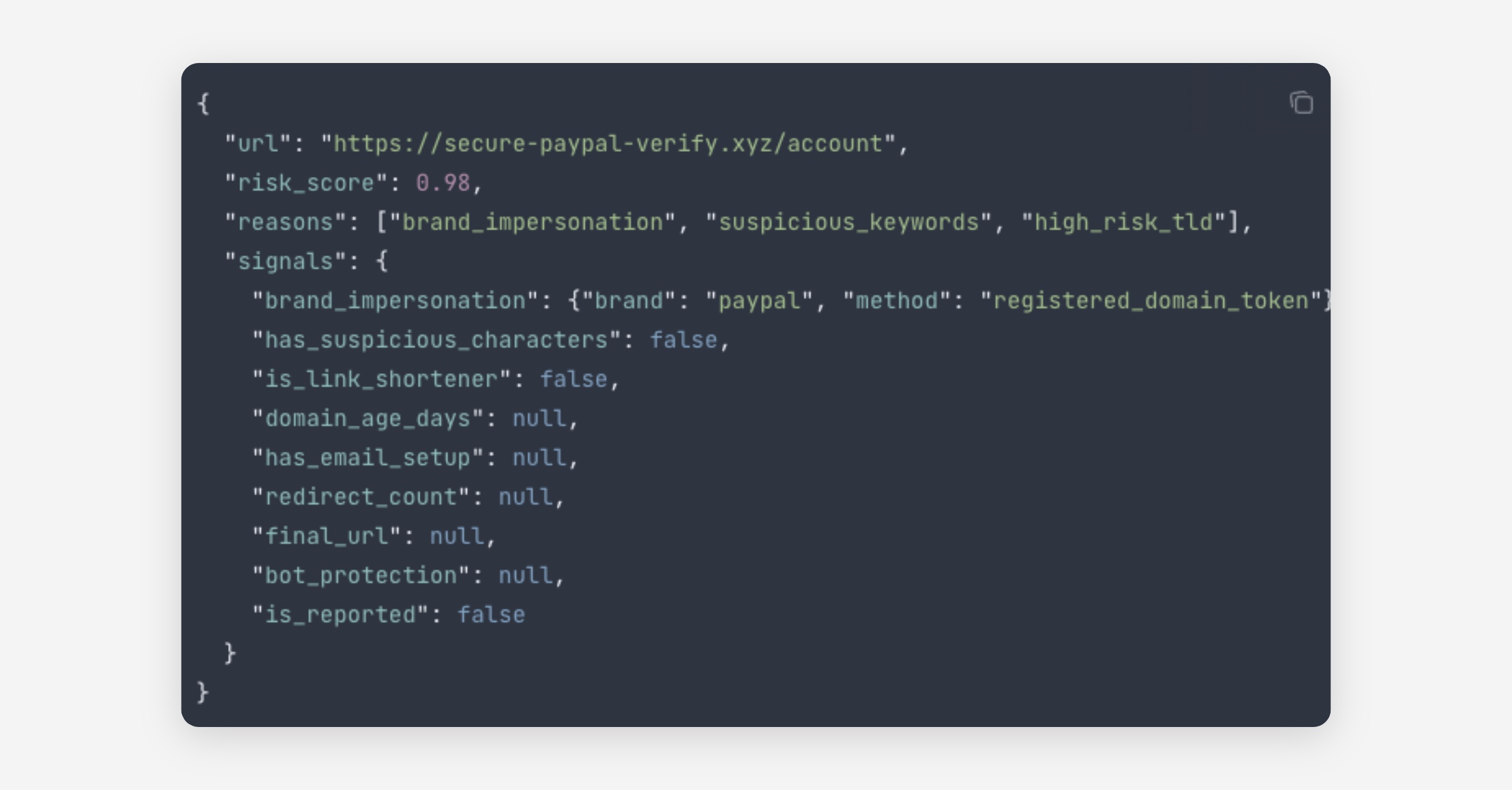
Available on all plans. Read the URL risk docs here.
Audio analysis
Submit an audio file and we'll transcribe it and run every text policy you have enabled. Toxicity, hate, PII, wordlists, guidelines, all of them. The review queue shows the waveform alongside the transcript. Most audio format works (mp3, wav, m4a, opus, and more), up to 50 MB or 10 minutes per file.
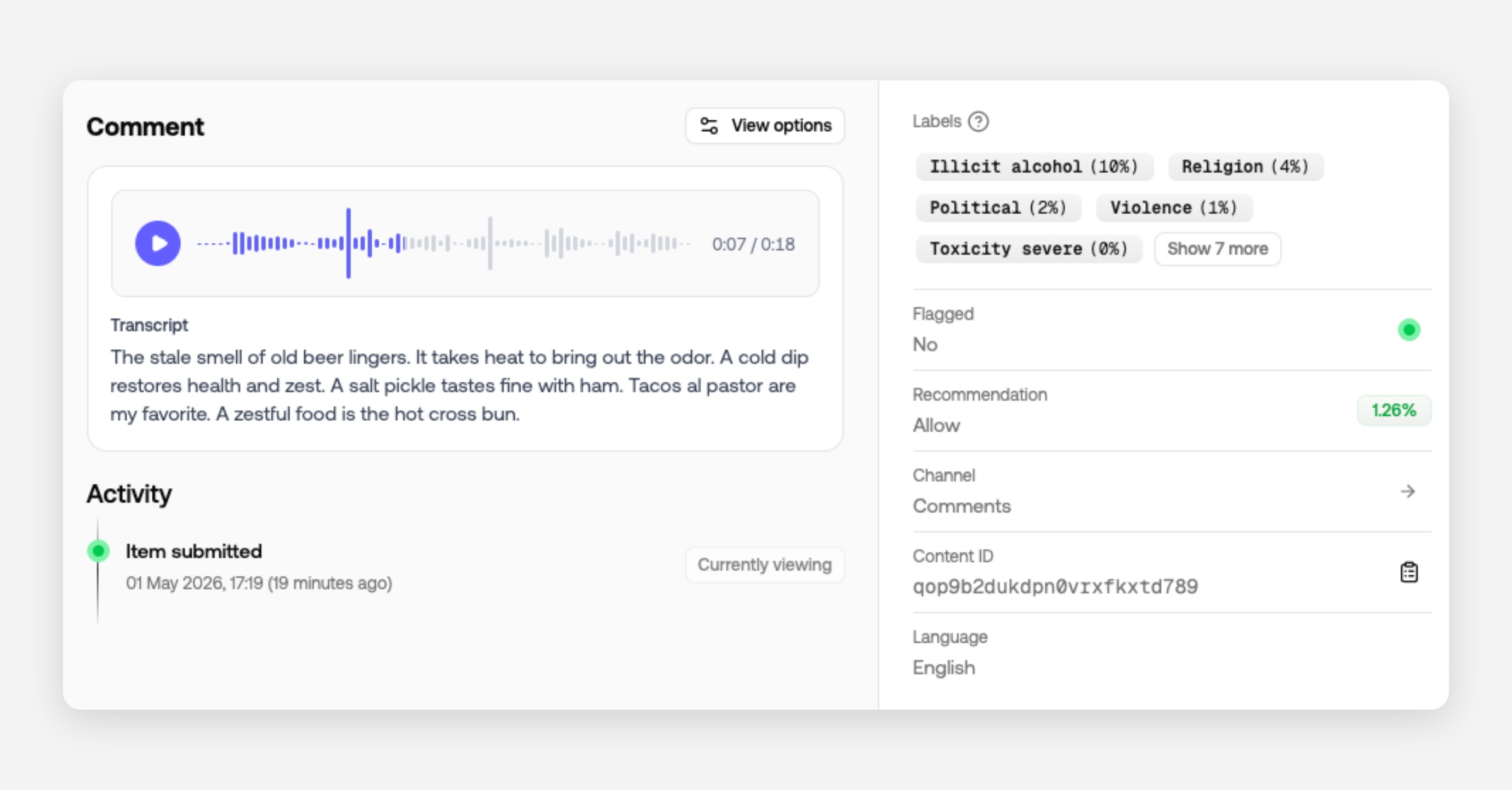
Available on request. Read about audio moderation here.
Reviewer wellness
Blur, grayscale, and default-muted video for the review queue. Project-wide defaults for high-risk queues, personal overrides per reviewer. Settings live on a separate page so nobody dials protection down mid-shift.
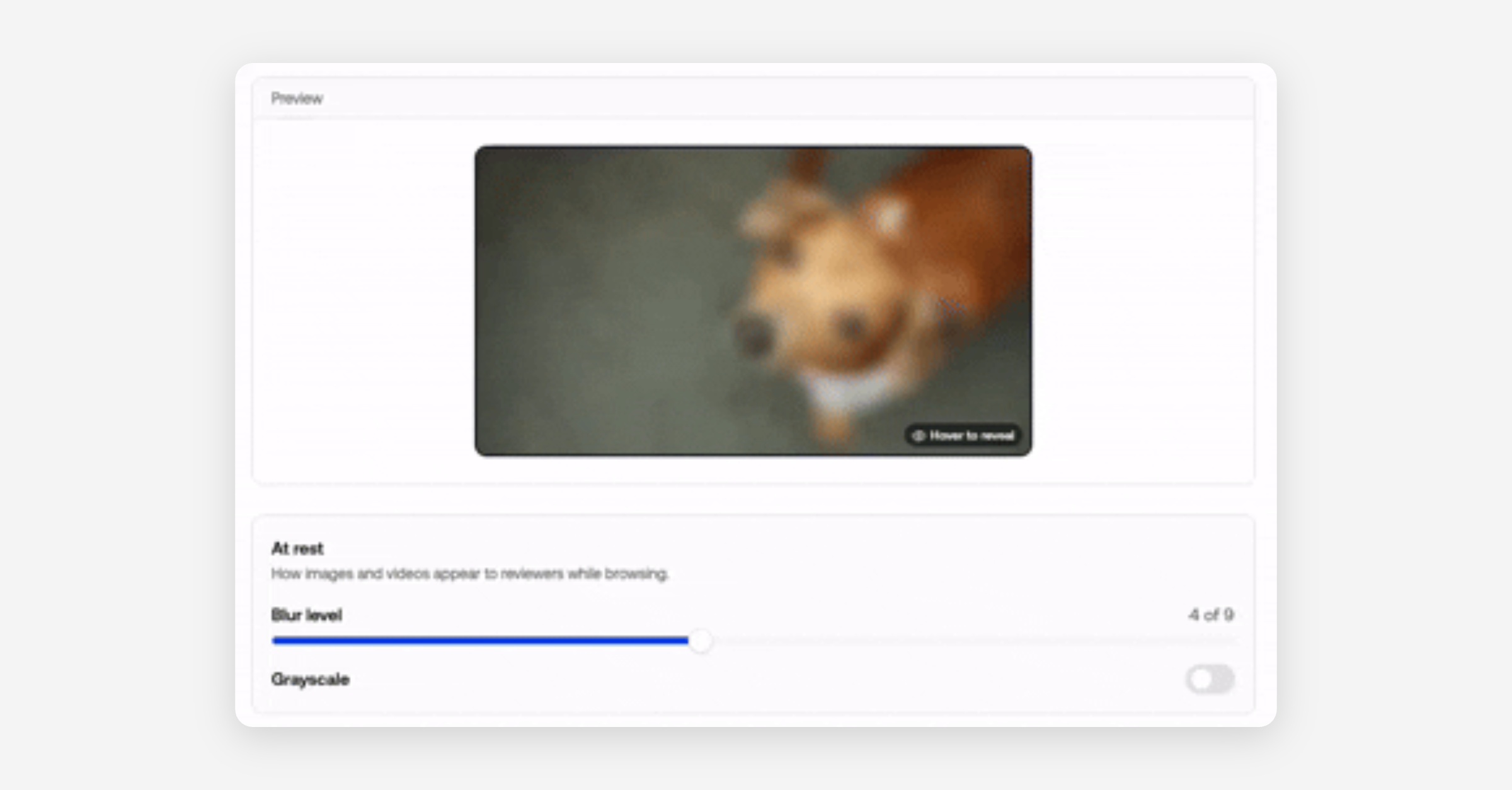
Available on all plans. Read more about reviewer wellness here.
Translation
One-click translation in the review queue — text, object fields, and audio transcripts. Tuned for moderation: slang, slurs, and coded language stay intact. Reused across your organization for 30 days.
Available on all plans. Read about translating content.
Also shipped
Inline entity highlights for URLs, PII, and wordlist matches in queue content
Project context now feeds into AI-generated guidelines
Slack plugin submits author profile pic and name
Faster URL risk verdicts when the call is clear from the URL string alone
March updates: 5 new models, email reports & shadow flagging

This month we're shipping several features that give you more control over how you monitor and tune your moderation setup - plus five new policy models covering regulated content categories.
Email reports
You can now receive email reports for new and unresolved queue items. Each queue can be configured separately, and each user manages their own notification preferences.
Daily, weekly, and monthly reports are available on all plans. Hourly reports are available on Growth and Enterprise.
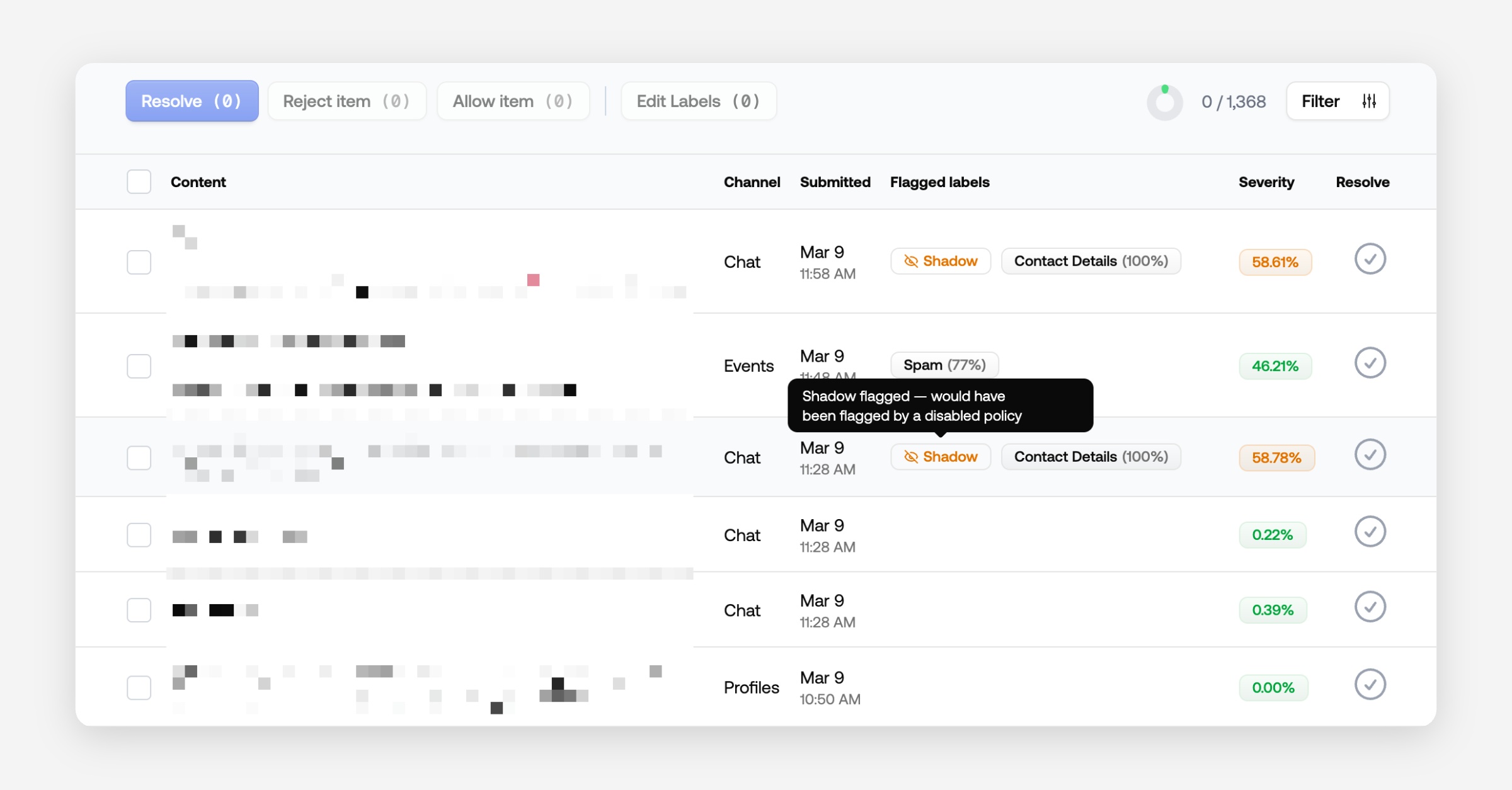
Shadow flagging
Shadow flagging lets you test new policies before fully enabling them. Items matched by a shadow-flagged policy appear in a dedicated queue but are not acted on. This gives you a safe way to evaluate coverage and tune thresholds before going live.
To enable it, set a policy to "Do not flag" and configure a queue to show shadow flagged content.
Available on all plans.
Policy thresholds
You can now set per-policy thresholds to control how strictly a policy is enforced. To help you calibrate, we show how many messages would have been flagged at any given threshold over the last 30 days.
Available on all plans.
5 new policy models
We've added five new models covering regulated content categories. Each is trained using our risk-based approach: content that poses a direct risk to the end user scores higher, while a passing mention scores lower. This lets you set a threshold that blocks promotional or facilitative content without flagging incidental references.
Adult: Detects content related to adult services, products, and websites.
Firearms: Detects content related to the sale, acquisition, or promotion of firearms and related accessories.
Gambling: Detects content promoting gambling services, platforms, or solicitations.
Crypto: Detects content related to cryptocurrency promotions, investment solicitations, and related financial schemes.
Cannabis: Detects content related to cannabis products, dispensaries, and related services.
Secondary features
Usage rate limit cadence indicator: You can now see your maximum request cadence directly in Billing → Usage & Limits, making it easier to plan traffic bursts and avoid throttling. Available on all plans.
Improvements
API: Switch to a 1-minute rate limit window for clearer, more predictable throttling behavior
Dashboard: Change overview percentages to show share of total messages instead of month-over-month deltas
Discord: Update Discord plugin to use the new endpoint; upgrade to the latest plugin version
General: Fine-tune topic detection for better categorization on edge cases
General: Retrain phishing model to reflect the latest tactics and improve precision
Improvement: Accept Base64 images in submission requests to simplify file handling
Improvement: Update WordPress plugin to the new endpoint; install the latest version to stay compatible
Improvement: Improve item detail load time for a faster review experience
Improvement: Save request timings so you can inspect end-to-end latency in logs
Performance: Speed up review queue queries for snappier filtering and navigation
Fixes
Bug: Author histogram now updates correctly after new data ingests
Bug: Author trust scores classify legacy accounts correctly instead of marking them as new
Bug: Insights now attach when adding policies through the API
Bug: Filter by action works as expected across all queue views
Bug: Resolve slow queries to stabilize response times under load
Bug: Now showing more accurate unique author counts in project overviews
🚀 Launch Week!

We're shipping new features every day this week. Check out what's new and what's coming.
Revamped dashboard

Next time you sign in to Moderation API, the dashboard will look, and work, very differently. We rebuilt it from the ground up to:
Make it easier to configure moderation policies
Improve the development experience
This redesign introduces channels, clearer project scoping, smarter content types, and a faster, more testable workflow.
Content channels
We’re adding a new abstraction: channels.
Think of channels as receivers for different content types. Policies are configured per channel, so each content type can have its own rules. In API calls, you just pass the channel key to apply the right policy set.
Examples for a marketplace:
Chat messages
Reviews
Listing descriptions
Profiles
Channels can represent anything that needs distinct rules: community trust levels, individual apps, client workspaces, and more.
Note: Existing “projects” have been converted to channels, with your previous filters mapped to policies. If you update your configuration, please use the new API endpoint.
Content types
Often our projects require moderating different types of content. Messages, websites, comments, profile descriptions, just to name a few.
Knowing which type of content is being moderated is beneficial for a couple of reasons;
It gives us context to improve the accuracy of the moderation.
We can display the content in a more meaningful way
For example for messages we can look back in the conversation history to gain context, and for comments we can check the relevancy of the article or post.
In the dashboard you'll see messages show up in the context of the conversations.
Profiles are displayed as structured objects (picture, description, username), making it obvious which field triggered a flag.
Configure content types per channel or include them in your API call when submitting content.
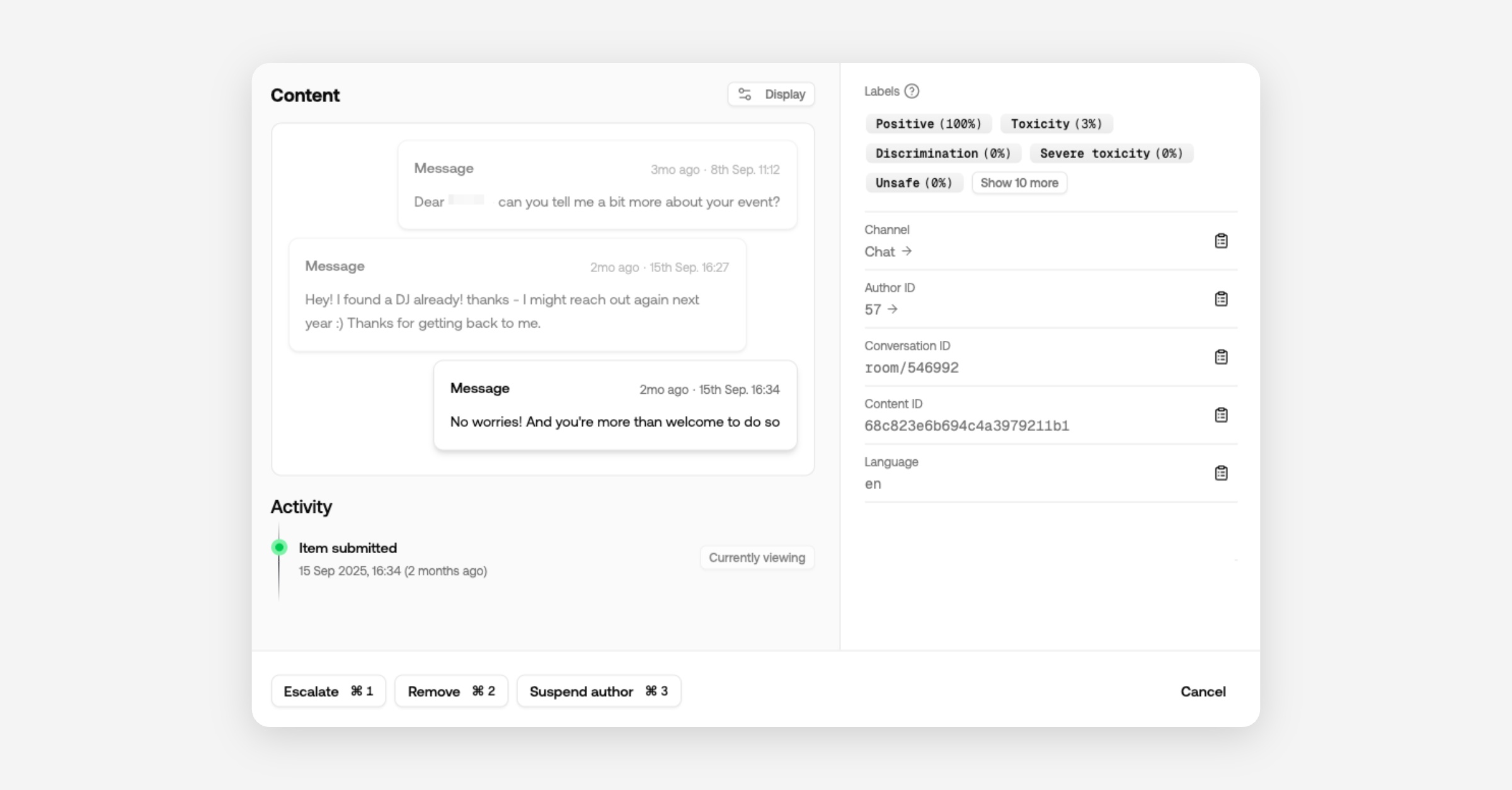
Projects
Projects now encapsulate all content and users. Review queues, channels, authors, API keys, and moderation actions are scoped to a single project.
That means you can create projects for different development environments to keep test content out of production.
Agencies can create a project per client and invite them to a dedicated review queue.
Custom models and wordlists remain at the organization level, so improvements roll out automatically to all projects.
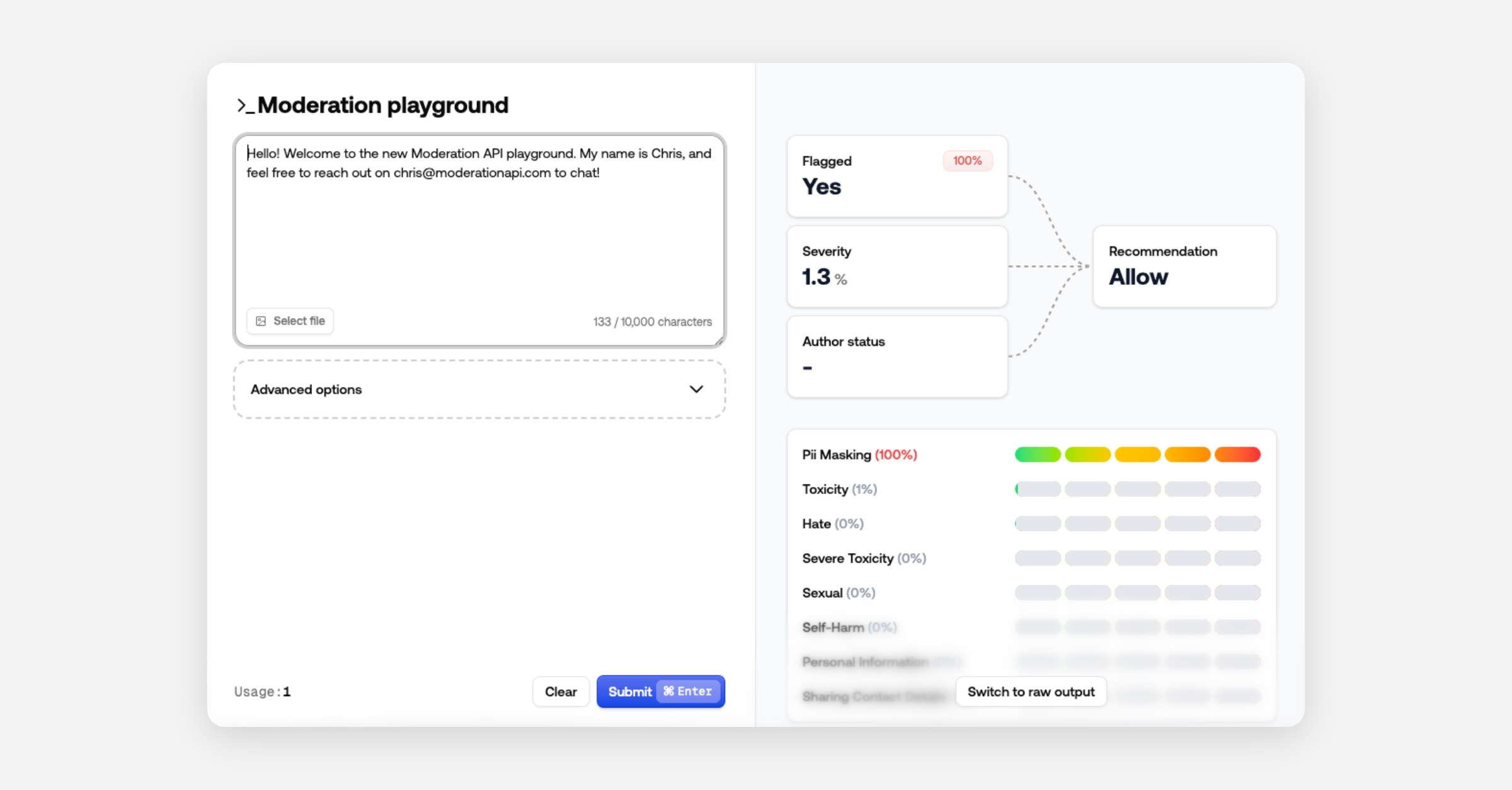
Playground
The Playground is now a modal for quick policy iteration and testing.
It also includes results of our new recommendation fields and severity score to show what contributed to the recommended action.
Prefer raw JSON? Switch views - the dashboard remembers your choice.
Other changes
Use channel ID or key in API calls (instead of changing API keys)
AI agents removed in favor of channel-level custom guidelines
Easier organization switching
Performance improvements and bug fixes
Press an author ID in the Content View to navigate directly to that author
Improved authentication
Content severity score in API result
Sort review queues by severity
Recommended action in API result - block, review, allow
Unified moderation API endpoint

We’ve consolidated all moderation routes into a single endpoint to simplify integrations and deliver richer, consistent responses.
New unified endpoint:
https://api.moderationapi.com/v1/moderate
Deprecated:
/moderate/text/moderate/image/moderate/object/moderate/video
The new endpoint streamlines submissions and introduces improved response data, including several new fields.
New response fields
Evaluation
The evaluation field is the final result of the analysis of your policies and other channel specific configurations. It includes a flagged field indicating if any policies caused a flag.
It also includes a new severity score which is calculated based on your selected policies. A higher severity score indicates more serious violations and lower severity less serious.
The severity score can be used as a granular indication, where the flagged field is a simple binary indication. You can also use the severity score to prioritize content in your review queues.
Recommendation
The response also includes a recommended action to help you decide whether to reject, review or allow content.
We recommend using this field for deciding what to do with content in your code.
This recommendation primarily considers severityScore and author status (e.g., blocked or suspended).
You can adjust the thresholds for blocking or reviewing in your channel configurations.
Policies
All enabled policies are returned as an array, each with:
id: the policy’s unique identifier (matches the dashboard)
flagged: whether this policy triggered
probability: the model’s confidence
Some policies include extra data (e.g., PII detection returns matched items).
How to migrate
Using typescript SDK
Upgrade the SDK to at least v2.0.1.
Recommended: Remove the api key from the constructor and add your project API key in your env variables as
MODAPI_SECRET_KEY.
Update all calls in the moderate namespace to use
content.submitand follow the new content structure.Recommended: Include your channel key; use different channels per content type.
Rename contextId to conversationId.
Read flags from
evaluation.flaggedinstead of the root flagged key.Recommended: switch to use
recommendation.actioninstead of flagged, and check forreject,review, orallow.
import ModerationAPI from "@moderation-api/sdk";
const moderationApi = new ModerationAPI();
const result = await moderationApi.content.submit({
content: { // new content structure
type: "text",
text: "Hello world!",
},
metaType: "message", // new field
contentId: "message-123",
authorId: "user-123",
conversationId: "room-456", // renamed from contextId
metadata: {
customField: "value",
},
});
// OPTION 1: Same behavior as before
if (result.evaluation.flagged) {
// Block the content, show an error, etc...
}
// OPTION 2: Use the API's recommendation (considers severity, thresholds, and more)
switch (result.recommendation.action) {
case "reject":
// show error, don't save to db
break;
case "review":
// save to db, but review in moderation API dashboard
break;
case "allow":
// save to db
break;
}Using API endpoint directly
Switch base URL from
https://moderationapi.com/api/v1tohttps://api.moderationapi.com/v1Replace all calls under
/moderate/{type}with/moderateand follow the new structure for content.Recommended: If you previously used multiple API keys for different projects, you can now use one key and pass different channel keys per call.
Rename contextId to conversationId.
Read flags from
evaluation.flaggedinstead of the root levelflaggedkey.Recommended: Prefer
recommendation.actionoverevaluation.flagged, and check forreject,review, orallowas shown above.
Dive deeper in the docs
See full API reference and content schema:
Severity score for content

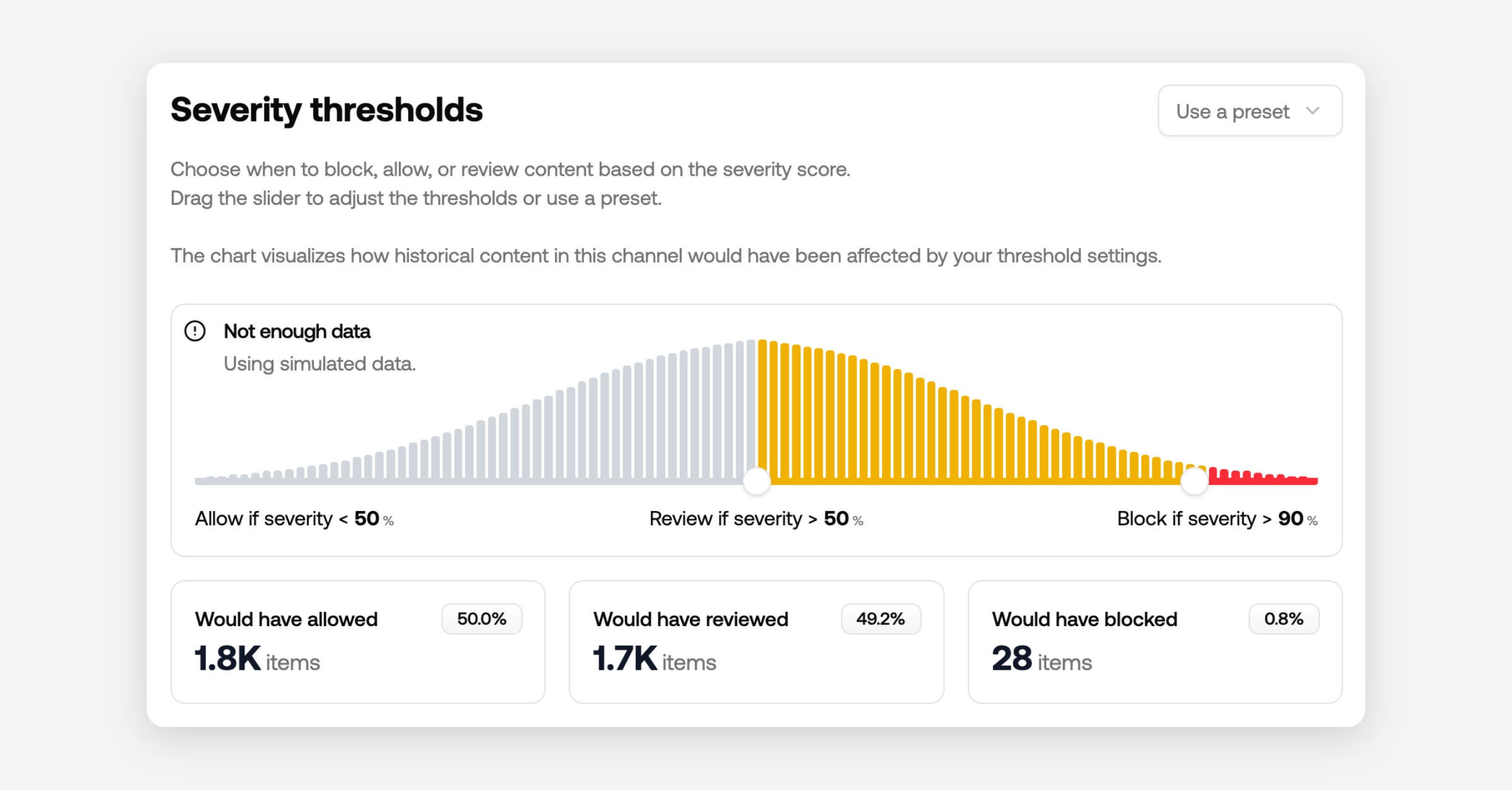
When multiple content policies can flag the same item, it’s hard to know whether a violation is minor (e.g., profanity) or critical (e.g., illicit behavior) without digging through each policy.
To solve this we've built a top level model to output a single score to give you an instant idea about the severity of a violation.
Severity score solves this by providing a single, opinionated score across all your policies. It weights violations by impact so you can see urgency at a glance.
For example: illicit content ranks above hate, which ranks above swearing.
Use severity score to:
Sort review queues by severity.
Set thresholds to automate actions (e.g., block above 90%, review above 50%).
Understand historical impact on your dashboard, including how many items would have been blocked. Note: historical data is available if you’ve used an API endpoint that supports severity score for the past 30 days.
Implementation:
Read the score at
evaluation.severity_score.Read the recommended action at
recommendation.action.
API improvements
You now get the author details in the moderation response.
New author endpoints to update, retrieve, and list authors.
Update authors with data to improve trust scoring.
Dashboard features
View Messages in Context: You can now see moderation items with surrounding conversation context for better decision-making
Image & Video Blurring: Added ability to blur sensitive images and videos in content view for safer moderation
Global Queue Option: New global queue setting available. This will remove content from queues if it has been reviewed in any queue.
Use variables in masking: You can now use $ variables in masking. For example, if you want to wrap matched words in
<b>tags, you can use<b>$</b>as the masking value.
Bug fixes and improvements
Improved dashboard performance and stability
New Author Dashboard

We’ve introduced a new comprehensive author-level dashboard system to enhance end user management.
New Author Detail Pages: Comprehensive user profiles with complete activity overview, trust levels, moderation history, and detailed analytics
Summary Tab: Trust level management, sentiment analysis, message statistics, and top violation categories
Timeline Tab: Complete chronological view of user activity with context grouping and advanced filtering
Fraud Detection Tab: Advanced behavioral analysis including bot detection, location anomalies, device fingerprinting, and risk assessment
Metadata Tab: Technical user information and account details
Trust Level SystemA new trust level system allows you to tailor moderation actions based on user behavior and find bad actors more easily.
Automated Trust Adjustments: System automatically adjusts trust levels based on user behavior and moderation history
Manually upgrade or downgrade trust levels as needed
Trust Level Impact: Trust levels can be consumed via the API or to influence moderation decisions, such as auto-approving content from high-trust users
Author-Level Moderation Actions
Comprehensive User Actions: Block, suspend, and unblock users directly from their profile pages
Duration-Based Suspensions: Flexible temporary blocks with customizable time periods (1 hour to 1 year)
Remember to set up webhooks to handle actions taken on authors